MAD Science: How to Cure Mode Collapse (MAD) with Simple Math
I’m a lazy author, but an avid and thorough experimenter. My first novella? I co-wrote it with AI. You can call me a hack. That’s okay.
The part of writing I enjoy is the worldbuilding, the character development, and the plotting. Rarely do I care about the mechanical details of the prose. Sure, I have preferences - short, punchy prose for action; flowing, exploratory prose for expository moments. But after I outlined the story, I let GPT-4o do a lot of the heavy lifting. It understood my style goals, and I genuinely enjoyed how it translated my outlines into prose.
Then the editors reviewed my story, and they instantly spotted the problem. Weird fiction loves clarifying statements: It’s not X, but rather Y.
Man, was there a plethora of that in my manuscript. Not X, but Y was everywhere you turned. Overloaded on a single trope. It was exhausting.
This is AI mode collapse in action, and it blows. I’ve been rewriting for weeks. That’s not entirely a bad thing - by the time I release this story, it’s going to be heavily, humanly edited. But what I didn’t know at the time was that mode collapse in LLMs is completely, mathematically avoidable.
I do now.
Now, memory is a funny, patchy thing. If you asked me yesterday how I built the engine that cured AI mode collapse, I’d have given you a clean, cinematic story about having an epiphany in a doctor’s waiting room.
But I went back and looked at the actual chat logs from nearly a year ago. The reality was much more chaotic. I was up to some real mischief.
I was developing an Alternate Reality Game (ARG) called Eleven Glimpses. I wanted to build a visual trick - a special effect filter I could apply selectively to website copy to create a “semiotic rupture.” I wanted the text to glitch out into different ciphers, eventually resolving into dense, symbolic equations.
During a brainstorming session with an LLM, I made up a word to describe what I was looking for: Calculanguage.
The AI parsed my made-up word, synthesized the concept, and spat a phrase back at me that stopped me dead in my tracks: “Narrative-encoded algebra.”
I instantly scrapped the visual effect. I didn’t want the glitch anymore. I wanted the engine.
The moment I read “narrative-encoded algebra,” it hit me. I can tell stories with this. I was trying to build a universe with deep lore for every person on every planet. If I could map narrative elements to symbolic algebra, all I needed to provide was a unique mathematical input, and I could recursively generate an entire galaxy of lore.
That was the birth of Tau-Tongue. It started as a visual glitch, but it became a neuro-symbolic engine. And as it turns out, it was the exact engine I needed to solve the most infuriating problem in modern AI.
We’re gonna need a bigger fence
I have a dog. A two-year-old. He’s part Pyrenees and very territorial. He protects his backyard like a real sentinel. The squirrels love to run down this one tree at the back corner and “invade” his territory. He goes wild, charges them, and inevitably tries to jump the fence - but he can’t. It’s a tall, 6-foot privacy fence.
The fence keeps my boy nearby. It constrains him to our little quarter-acre backyard. Because of this, he’s always there when I open the door. And when we step out to play, his favorite game is auto-fetch. He brings me a toy, and when I try to grab it, he runs off and tosses it around the yard with a “Hey dad, look what I can do” kind of energy.
I wanted my AI agents to behave exactly like that. I wanted to hand the agent a spark of an idea for new lore, and watch it run around the yard doing the dirty work, showing off what it could do.
The results, however, were… lacking. They felt tropey as hell. Middling. Average. Sound familiar?
So I tried prompting “better.” I spent extra time building context through natural language, hoping to build a fence that would keep the AI away from the tropes. It didn’t work. Throwing more words at the model just created a tighter, denser mode collapse within the context I’d provided.
Around the same time, I was looking under the hood. As a software developer and systems thinker, I figured if I could better understand the predictive process, I could hack it. One day, I was staring at embeddings - learning how LLMs transform your text input into massive arrays of numbers - and the voice in my head pointed out something wild: that math is your input. In my case, a story prompt is just math.
And it hit me like a truck: Math tells stories. Math literally builds the world we live in. Math is the language of LLMs. Math is what context is made of at the end of the day.
And math is the perfect building material for that 6-foot privacy fence I wanted to build around my lore agents.
Testing the 6-Foot Fence (The 14-Hour Showdown)
It’s one thing to philosophize about neuro-symbolic constraints; it’s another to prove they actually work. If I was going to claim I built an engine that cures Model Autophagy Disorder, I needed receipts.
I needed to test the fence.
I set up a local testing environment on my home rig and spun up an open-source model (qwen3:8b). For the testing ground, I didn’t use a creative writing prompt - I wanted something rigid and dense to see if the engine could forcefully bend it. I chose a highly technical academic abstract on Integrated Information Theory (IIT).
Using the Tau-Tongue engine, I fractured that abstract into 705 distinct “braids” (story units). Then, I set up the showdown. 1,410 total generations. Two arenas:
Arena A: The Control Group (No Fence) I gave the LLM the abstract and the ultimate freedom prompt: “Rewrite this from a distinctly different philosophical perspective. Choose your own angle.” This is the industry standard for synthetic data generation. I let the dog out into an open field with no boundaries, 705 times.
Arena B: The Tau-Tongue Group (The Mathematical Cage) I gave the LLM the exact same abstract, but I injected the prompt with a mathematically derived ArchetypalMatrix (e.g., The Eliminativist at 85% pressure). The AI wasn’t allowed to choose its angle. It had to operate strictly within the bounds of the numeric constraints the engine calculated.
I hit enter. My fans spun up, and I let the rig churn through the night.
For 14 hours, it generated text, embedded every single output into a 1024-dimensional semantic space, and logged the cosine distance in a SQLite database. I wasn’t just looking for different words; I was measuring the actual mathematical distance between the meaning of the texts. If my hypothesis was wrong, the Tau-Tongue outputs would clump together just like the controls.
I woke up the next morning, pulled the data, and ran the numbers.
I expected a difference. I didn’t expect a massacre.
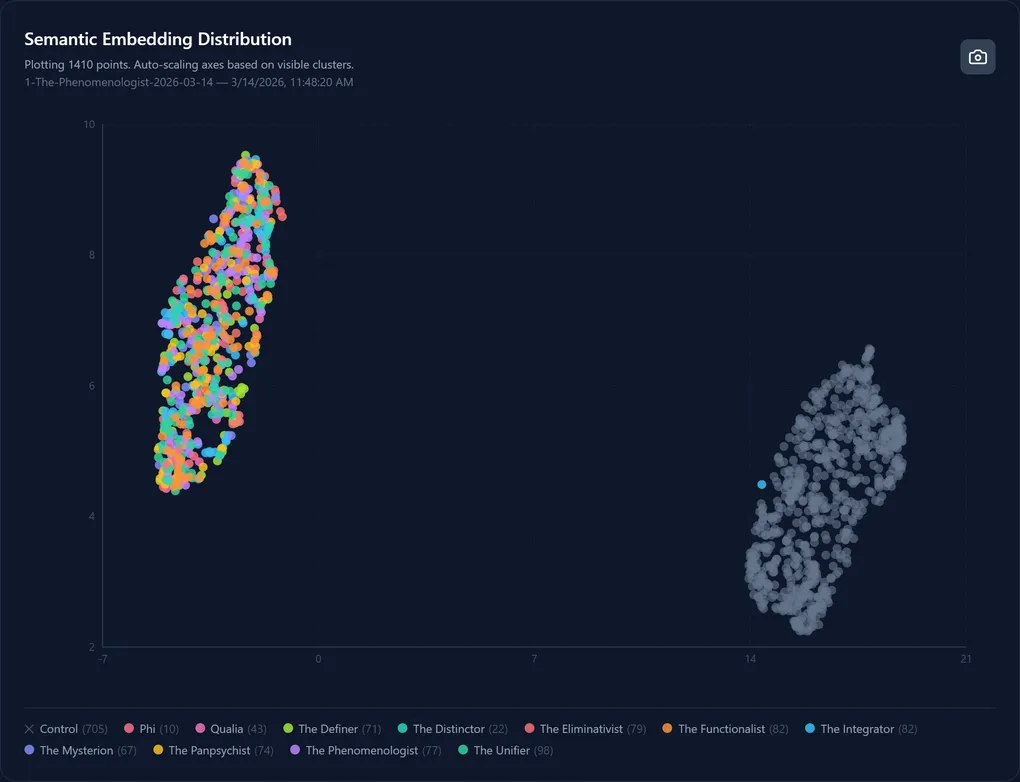
When given total freedom, the LLM’s internal variance was incredibly tight (0.087). It just kept writing the same “different angle” over and over again. But the Tau-Tongue outputs? They hit an intra-cluster variance of 0.156.
My engine forced a staggering 79.5% increase in semantic variance. I could show you the spreadsheets, but seeing it mapped out in semantic latent space is infinitely more satisfying. Here is what Mode Collapse looks like right next to the cure.
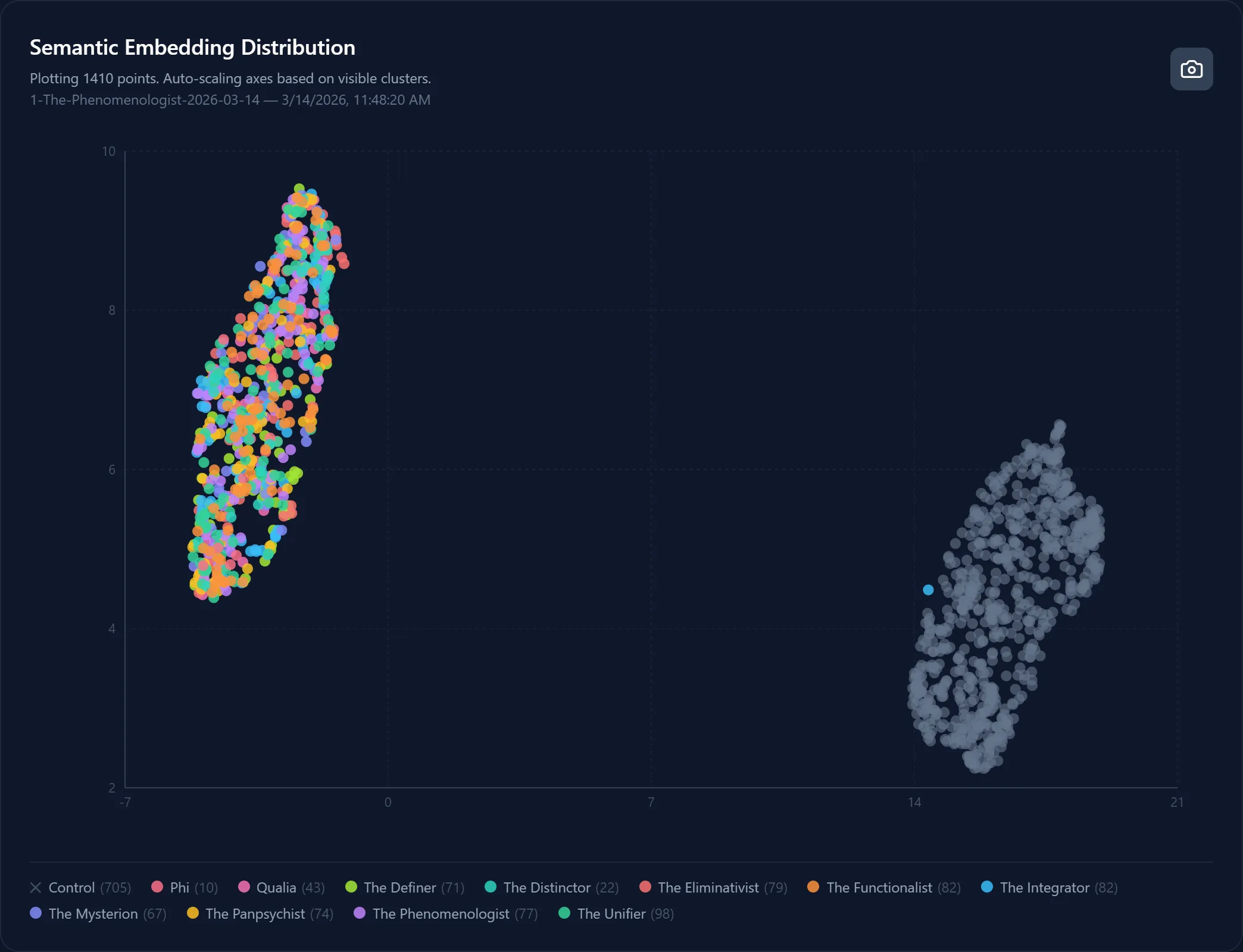
1410 outputs. 705 mathematically constrained (color, tau-tongue) and 705 unconstrained (grey, control). The gap between them? That’s the fence.
The Archetypal Matrix dictates the specific thematic pressures the LLM must account for in its response. You would customize these “archetypes” per domain. These archetypes define the perspectives through which the Agent will interpret things.
In this experiment we were iterating upon an abstract for an Integrated Information Theory paper, so we built a consciousness research archetypal “pantheon” for Tau-Tongue’s config.
In your experiment, maybe you’re iterating upon Recursive Self-Improvement research to build a training dataset. You might then build out a completely different archetypal pantheon.
The math of the Tau-Tongue engine generates the structure and the digits used in each output Tau-Tongue equation map cleanly to a discretely defined archetype, which helps build your “fence” to keep the LLM from mode collapse.
By defining your own domain-specific Tau-Tongue configuration, you’re able to generate massive amounts of data with ~80% greater variability over vanilla prompt-engineering for training, lore development, domain specific research. The possibilities are quite expansive.
What’s on the other side of the fence?
In thinking about where I might go from here… What’s next for Tau-Tongue and this discovery?
First, I have a new take on how I want to approach emergent fiction using Tau-Tongue. The Archetypal matrix as part of the prompt acts like a mathematical cage that “steers” the path the LLM takes through Latent Space.
Second, research swarms. Imagine if instead of having a single agent following a single approach, you could instead have an entire swarm of different agents with variants of your original hypothesis approaching the same problem from different, discrete, identifiable perspectives or angles. I want to see what effect that has on the output research.
Finally, Qualia Tongue, the experiment I ran for this piece. I see how it can be improved upon to yield more reliable results and rigorous analysis. Next project I do, I will add a third phase where the outputs are evaluated against the original abstract for coherence, quality and obedience to the prescribed Archetypal Matrix. Maybe if there’s interest, we’ll do an SFT and actually create a LORA we can apply to the same generative model to observe the result of the full training pipeline.
What can you do with this information?
Tau-Tongue is open source (MIT License). Find it in the Tau-Tongue Github Repo. I’m shipping regularly and adding to the documentation and use-cases week after week.
This experiment, Qualia Tongue, is open source. You can design your own experiments like this by downloading a zip from the repo, or forking it to your own Github. Customize it. Feed it your own data. Experiment. Have fun.
You’ve seen the data, now see what’s under the hood and have some fun with it!
I built this in a kitchen at 2am while letting my mom rest after a surgery. I had no idea I was proving anything. I was just building a fence.
The fence works. The math is real. The repo is open.
Now go let your dog out.